benzhan
949747fb92
1
benzhan
949747fb92
1
|
vor 5 Jahren | |
|---|---|---|
| .. | ||
| README.md | vor 5 Jahren | |
README.md
#规则
新建规则,规则对应需要抓取的相同类型的网页,比如列表页,详情页 无论是 /list?page=1 还是 /list?page=n 只要是抓取这个类型的页面获取的数据结构一样的都可以归类成一个规则内

规则id是唯一的
示例url是此规则的举例url,在此url上写采集规则
请求模式:普通和浏览器模式,默认普通模式,如果页面是js渲染的则用浏览器模式
数据类型:html/json,如果是爬取的api那么使用json,如果是普通页面则用html
等待条件,如果是请求模式选择浏览器模式,那么爬虫会根据这里设置的等待条件等待页面加载出这个等待的元素后才回调返回此页面的渲染好的html
页面预处理,可以在爬虫获取返回html后先处理页面html,然后再接下去用选择器获取去页面数据,比如有些页面是404,此404是一张图片,如果是直接传下去给选择器,那么会报错缺少字段,如果是预处理时就判断是否404图片,那么直接返回当做抓取成功不会进入选择器。$html, $, page,_task, JTool, Tool 这几个变量可以直接使用,在爬虫内部定义如下:
async _preprocess(content, page) {
if (this.rule.data_type === 'json') {
content = content.trim();
let lastChar = php.substr(content, -1);
if (lastChar === ')') {
let pos = content.indexOf('(');
content = content.substr(pos + 1, content.length - pos - 2);
}
}
let preprocess = this.rule.preprocess && this.rule.preprocess.trim();
if (preprocess) {
let func = php.create_function('$html, $, page, _task, JTool, Tool', preprocess);
let $ = null;
let $html = null;
if (this.rule.data_type === 'html') {
$ = cheerio.load(content, { decodeEntities: false });
JTool.initJquery($);
$html = $('html');
let flag = func($html, $, page, this.task, JTool, Tool);
if (flag === false) {
this.skip = true;
}
return $('<div></div>').html($html).html();
} else if (this.rule.data_type === 'json') {
$html = content;
return func($html, $, page, JTool, Tool);
}
}
return content;
}
#选择器
选择器负责拾取页面的数据,在浏览器上用js调试,可以立马生效查看获取的数据,这是可视化的基础,而不必如同其他爬虫一样需要每个网页手写不同的选择器

- 选择器:查找页面元素并返回
解析$el:上面选择器获取的节点元素,返回的变量用 $el 表示,和jquery操作节点元素一致
可用变量如下 _task:任务对象,[ 'url', 'rule_id', 'task_id', 'task_key' ] JTool.fixColspan($table, $): 展开表格colspan,删除不合法的列 JTool.formatDate(date): 把int/Date类型的数据,格式化为:Y-m-d JTool.formatDateTime(date): 把int/Date类型的数据,格式化为:Y-m-d H:i:s JTool.formatUrl(url): 把相对地址变化成绝对地址 JTool.formaRichText(content): 富文本的图片相对地址变化成绝对地址,去掉script标签 JTool.md5(str): md5加密- Next规则id:指定当爬取玩此规则后进入的下一个规则,可以设置上下文逻辑,比如列表页面的下一个规则应该是详情页
- 选择 单项/多项:如果是爬取的数据是多行的则选择多项,如果是只有一项那么选择单项。这里插入的逻辑是,如果是多项的取各个列名字段相同下标的数据处理组成一条数据记录插入数据库例如: ```js a 列名:选择多项获取到的是一个数组 ['a', 'b', 'c'] b 列名:选择多项获取到的是一个数组 ['d', 'e', 'f']
爬虫会将上面的数据格式化成: [['a','d'], ['b','e'], ['c','f']] 逐条插入/更新到数据库 ```
数据-仅插入/更新/仅更新:仅插入(insert)是当数据是新数据的时候插入到数据库,第二次爬取的时候数据不会再更新入库,更新(replace)是当第二次爬取的时候会执行更新到数据库,仅更新(update)是第二次爬取的数据和当前的数据库的数据不一致才会入库更新
必填:如果是在选择器分析页面数据中没有此字段,那么会报错,如果是可选,则不会报错
开关:开启后选择器会解析页面抓取数据,否则不进入此选择器的逻辑
转存:如果是图片,可以将此图片转存至自己服务器然后更新到数据库,这是一个异步的过程,入库后,转存脚本会扫描需要转存的数据,如果没有转存则将其下载到bs2然后重新将新的资源url地址更新到数据库内
只填充:只填充的字段,只在更新模式有效,选择器获取的数据会和临时表中上次抓取的老数据对比,老数据不存在时才填充
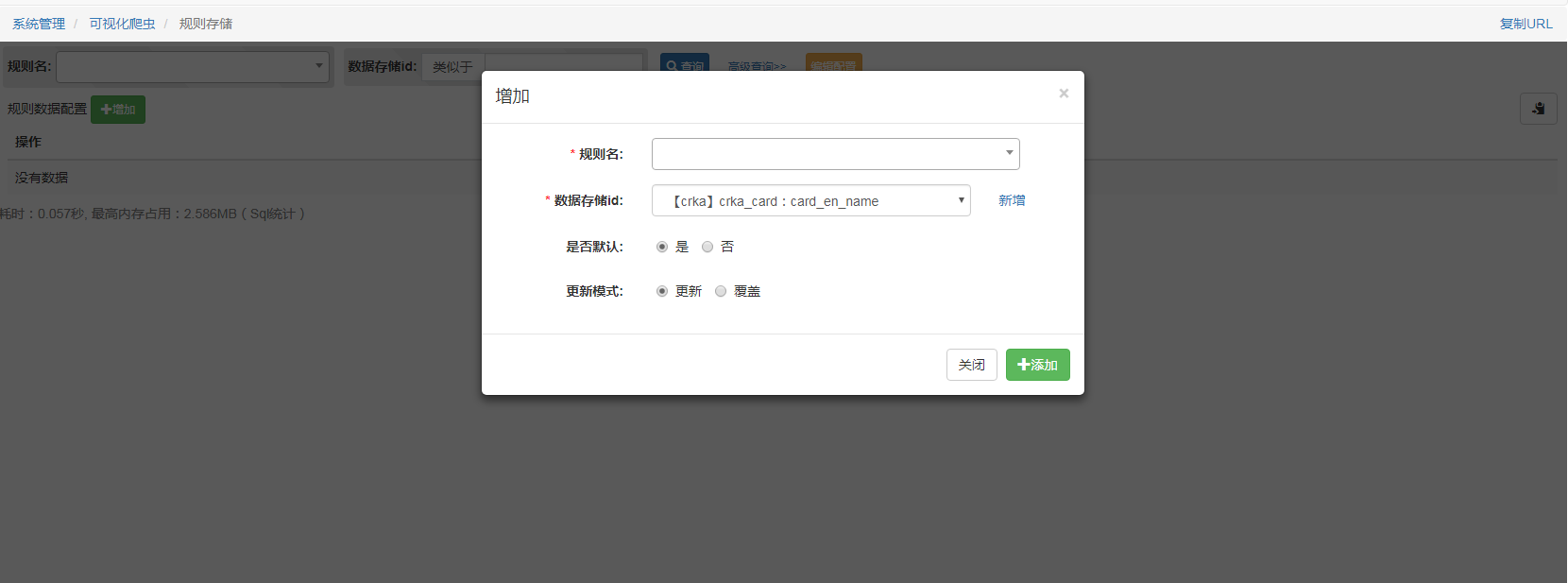
#配置库表
爬虫的数据库表从名字服务器内的配置拉取到表 db_table,data_db中,这里需要注意的是,当名字服务器发布新的数据库配置后,需要重启node进程才能让爬虫的配置生效

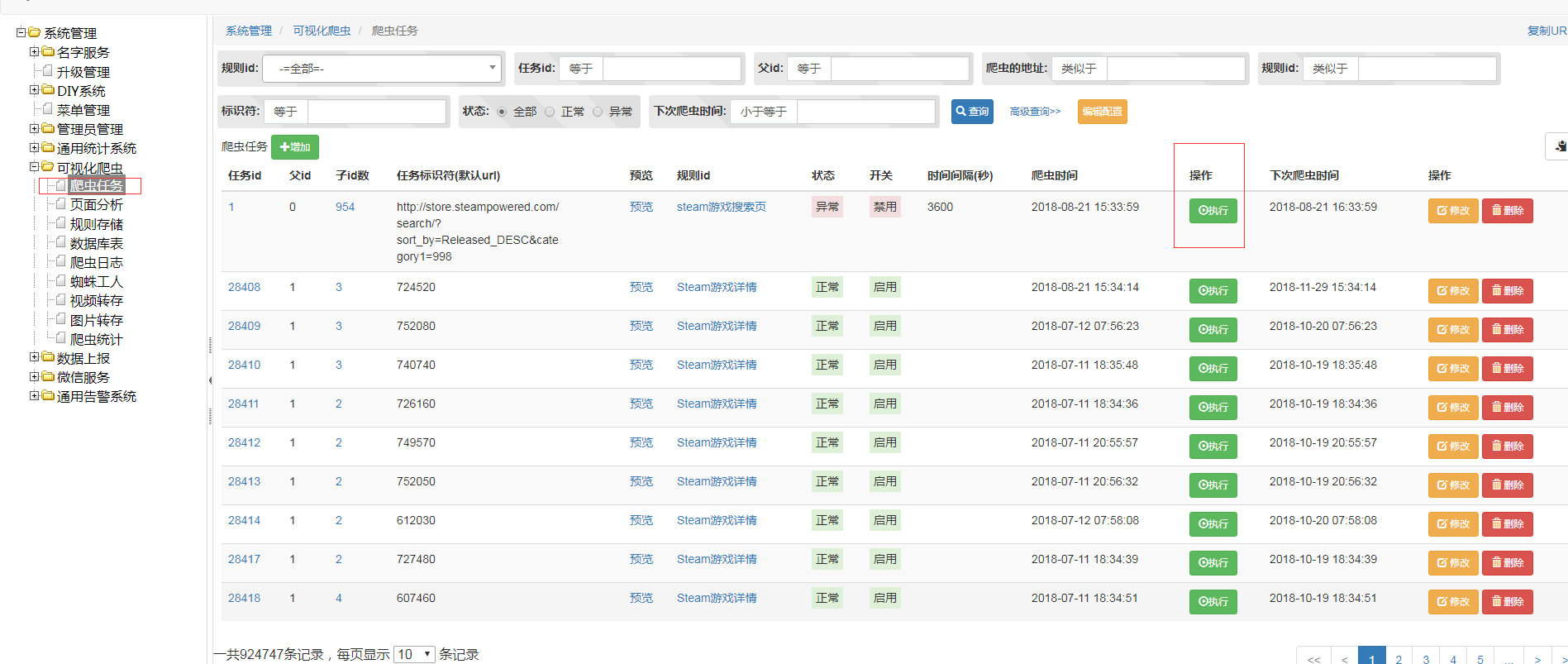
#任务
当规则添加后,需要配置任务,爬虫才能进行入库
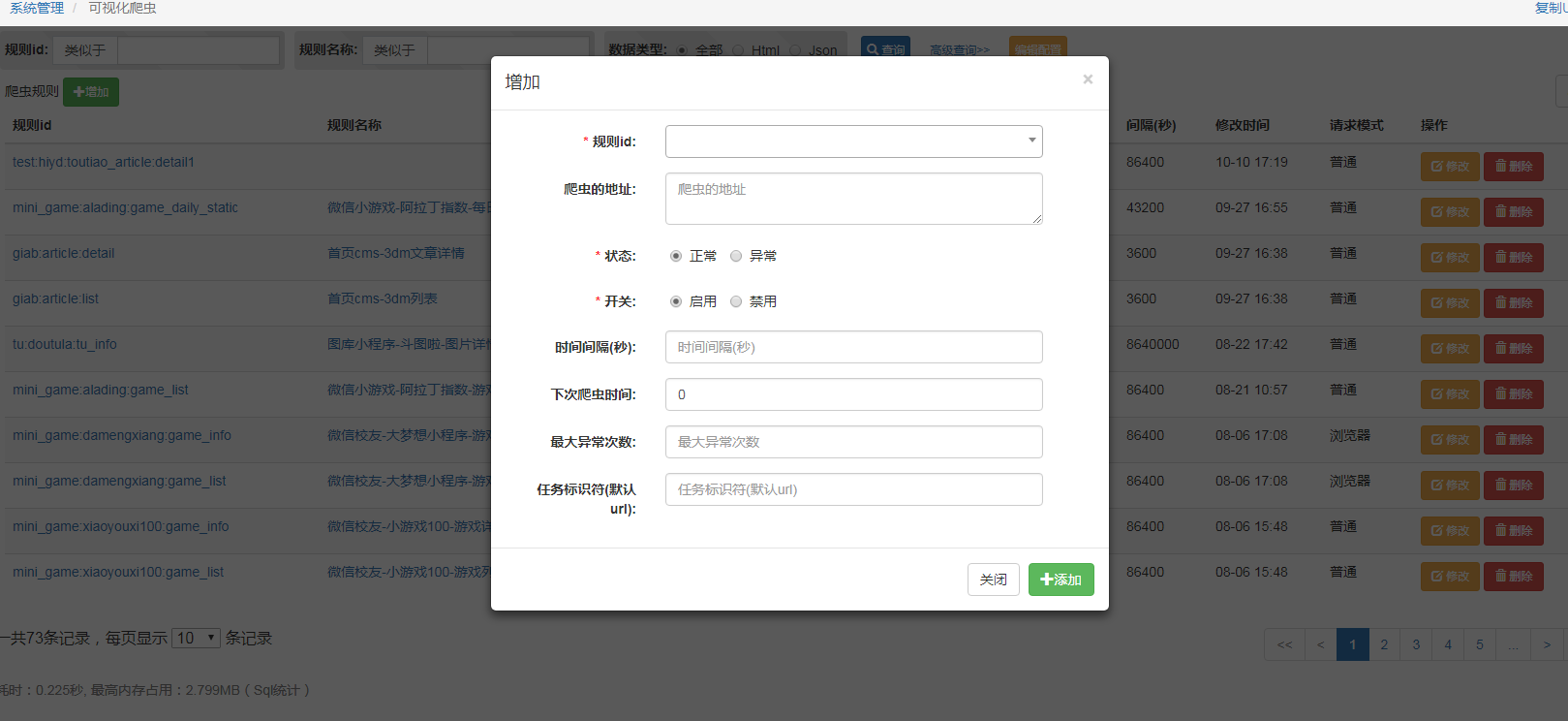
- 爬虫的地址:指的爬虫的初始入口url,爬虫任务根据此url,开始爬取,如果你配置了Next规则id,那么爬虫当爬取完此规则后会自动进入下一规则,这样就实现了上下问逻辑的网页爬取
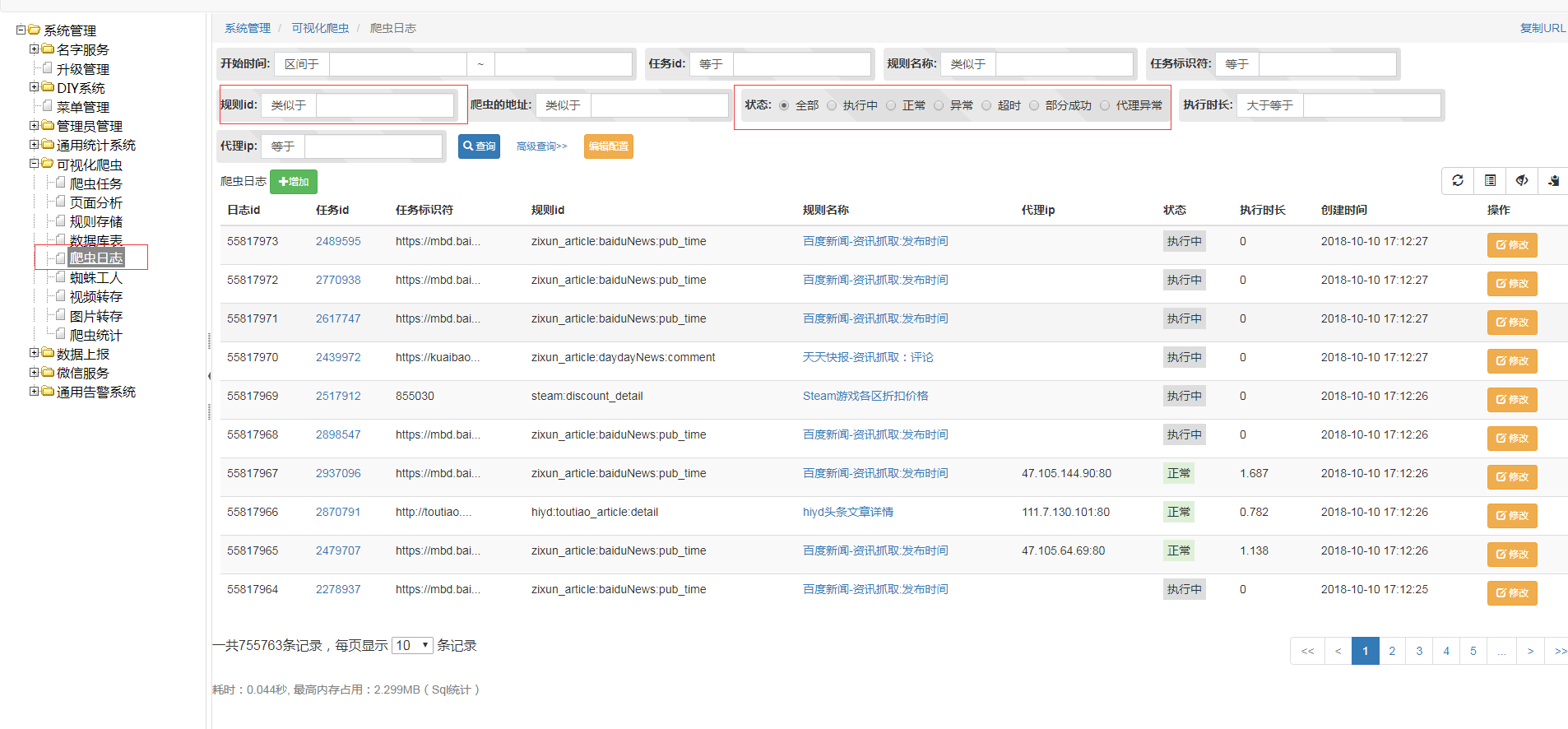
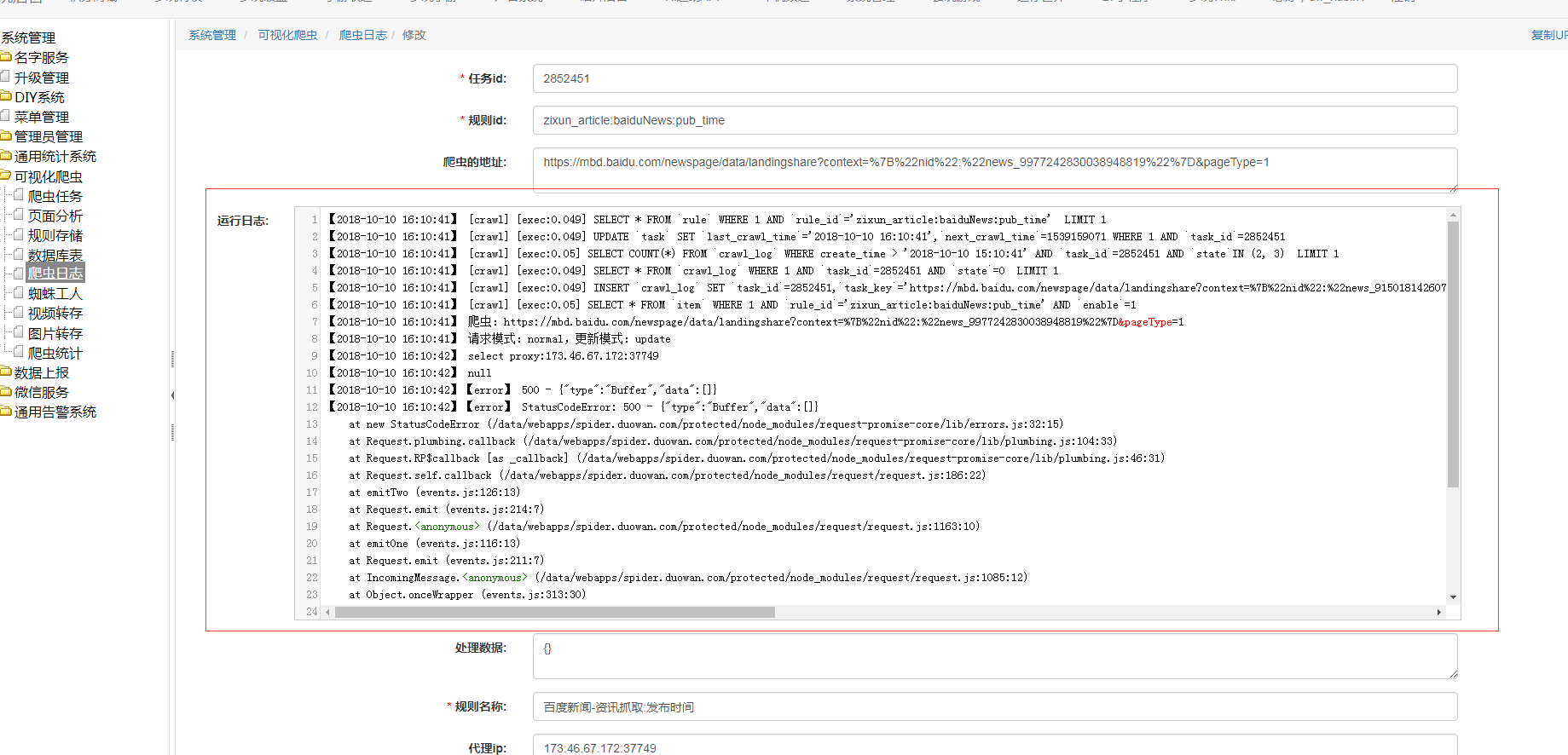
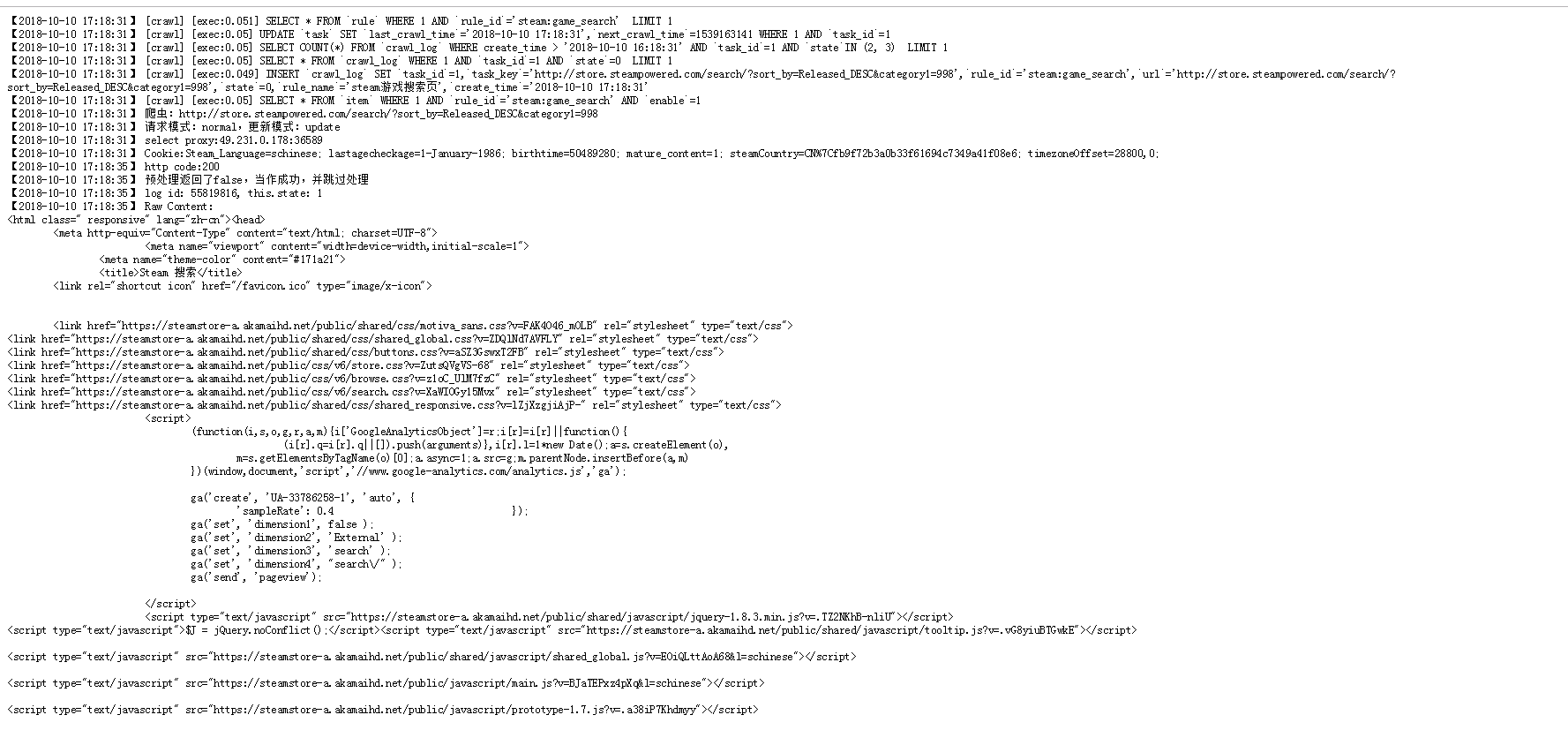
当添加完任务后还可以在网页上尝试点击执行,网页返回的是此任务执行期间的打印的日志
#调试
通过日志和网页运行爬取任务可以调试一个规则是否有报错